
Check out the new and improved site - CRADLE - for more features and better resources!
Use coupon code: REVPP20 for 20% off for 12 months! Cancel any time!
Use coupon code: REVPP20 for 20% off for 12 months! Cancel any time!
After a recent update, ReversePP began directly indexing data from planning application PDFs, solving the issue of mislabeling by councils. This change has prompted inquiries about applying similar methods to other tasks. As an OSINT or Multi-Source analyst, you might encounter situations where extracting information from numerous PDFs manually isn't practical. Although OCR/scanning software exists, it might not fit within your budget, necessitating a custom solution. This article outlines the workflow I employed, aiming to offer guidance for those who need to develop a similar process.
The workflow I used uses several open source algorithms capable of:
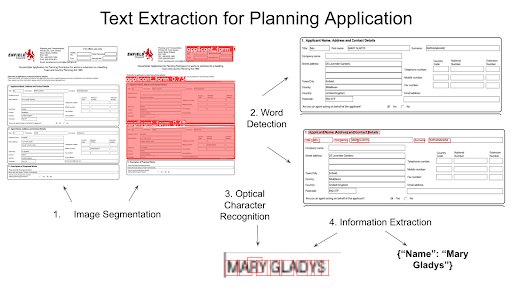
Deep learning stands out as the best approach for building models capable of executing intricate tasks. This form of supervised learning demands a considerable volume of trustworthy data for precise functioning. Nevertheless, one can utilise pre-existing image recognition models and refine them with a modest quantity of labelled data. Fortunately, acquiring and labelling a sufficient number of planning applications to identify the essential sections was a straightforward process given the data indexed by ReversePP. For each application a file was produced, detailing the class and the polygon outlining each identification document. There are several open source image annotation pieces of software available, I used this project developed at the University of Oxford. There is then a very useful Google Colab project made available here by RoboFlow which retrains the last layer of the YOLOv7 object detection model. It is then possible to download the new weights for that model for use locally.
There are many models available for word and text detection, I selected DBNet due to its strong reputation and integration within the Doctr GitHub repository. DBNet is particularly effective at processing datasets containing non-standard text, which is advantageous since a significant number of the application forms ingested by ReversePP contain handwritten text
Some difficulties were experienced due to the intersecting bounding boxes and the diverse formats of application forms used by different councils. This diversity led to the need for custom code to be written to precisely align the extracted data with its relevant fields. The development of this process was crucial for ensuring that the extracted information was accurate and correspond exactly to the designated areas on the forms. The task involved not only distinguishing text within overlapping areas but also adapting to the array of layouts and presentation styles unique to each council's documentation. This required an understanding of the forms' structures and the implementation of a flexible codebase capable of handling such variability with high precision.
This article has detailed a viable methodology for OSINT analysts au fait with programming and developers facing the daunting task of parsing vast quantities of PDF data without the luxury of extensive resources. The process outlined here underscores the incredible potential and adaptability of open-source tools and community-driven projects, from image segmentation to OCR and information extraction.
Data is both a commodity and a catalyst for innovation, the ability to efficiently transform unstructured data into actionable insights is invaluable. ReversePP's indexing capabilities is a testament to the power of machine learning in overcoming the limitations of traditional data processing methods. By leveraging advanced algorithms like DBNet and the retraining capabilities offered by platforms such as RoboFlow, we can address the nuances of irregular texts and the imperfections of document quality.
As technology continues to evolve, so too will the tools and methodologies for data extraction. This article serves as both a technical guide and a source of inspiration for future endeavours in the field of OSINT. The integration of deep learning techniques in practical applications like ReversePP not only enhances efficiency but also paves the way for more innovative approaches to data handling in the public sector and beyond.